基础教程
您现在已经安装了Crawlab,并且可能迫不及待地想要开始使用它。在深入细节之前,我建议您先浏览一下这个快速教程,这将帮助您了解一些基础知识并熟悉Crawlab中的主要功能。
介绍
在这个教程中,我们将创建一个爬虫,该爬虫会抓取模拟站点上的名人名言(由Zyte提供,即Scrapy背后的公司);然后我们将运行它来抓取数据;最后,我们将在Crawlab上以可视化方式查看抓取的数据。
我们将使用的框架是Scrapy,这是一个用Python编写的最流行的网络爬虫框架,易于使用且具有许多强大的功能。
创建爬虫
首先,我们将在Crawlab上创建一个Scrapy爬虫。
打开浏览器并导航到http://localhost:8080,使用默认用户名/密码admin/admin登录。
然后转到爬虫页面,点击左上角的新建爬虫按钮打开创建对话框。
在对话框中,选择模板为"Scrapy"并保持其他选项为默认值。然后点击确认创建爬虫。
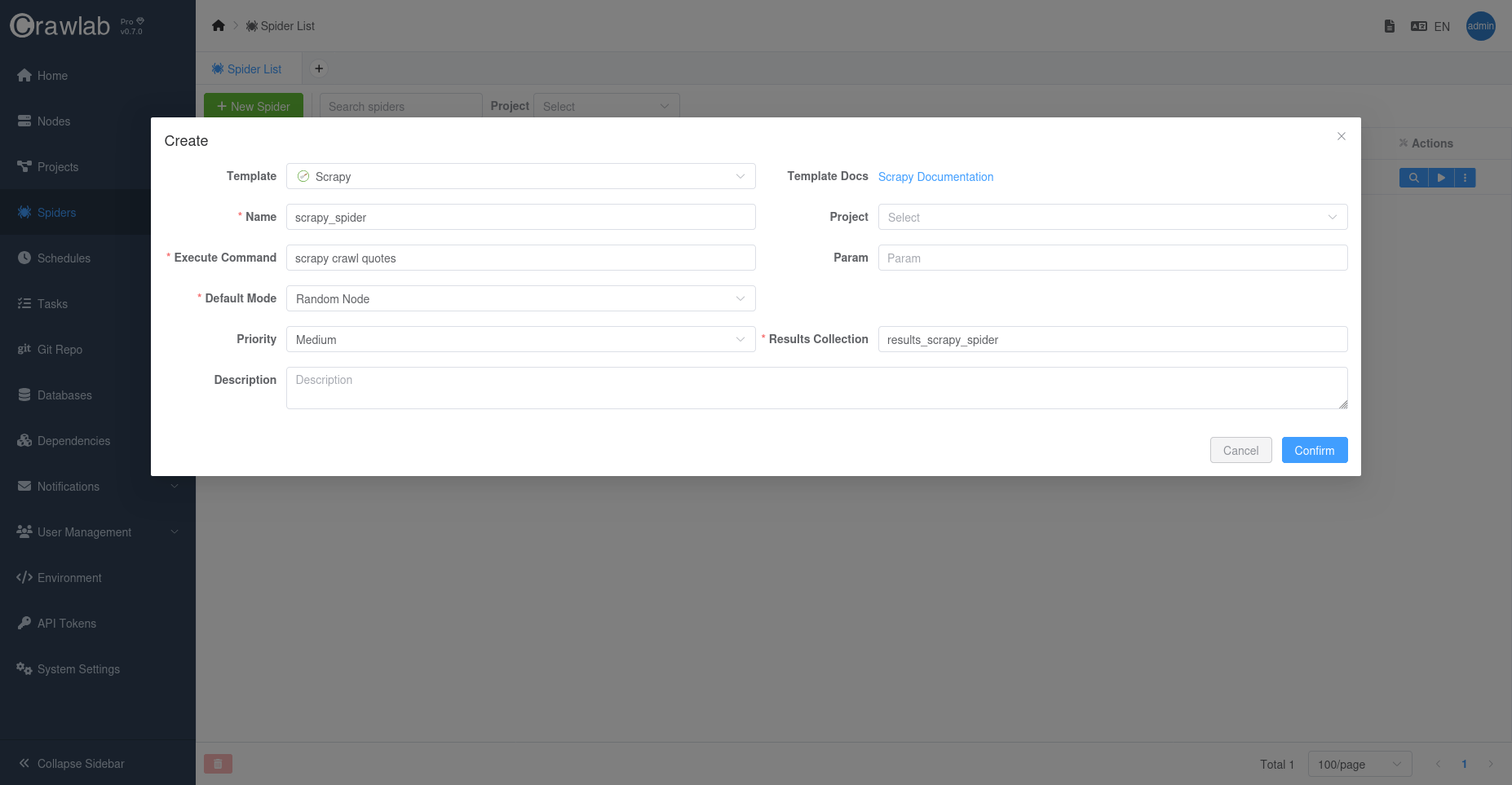
现在您应该能在爬虫页面上看到新创建的爬虫。
运行爬虫
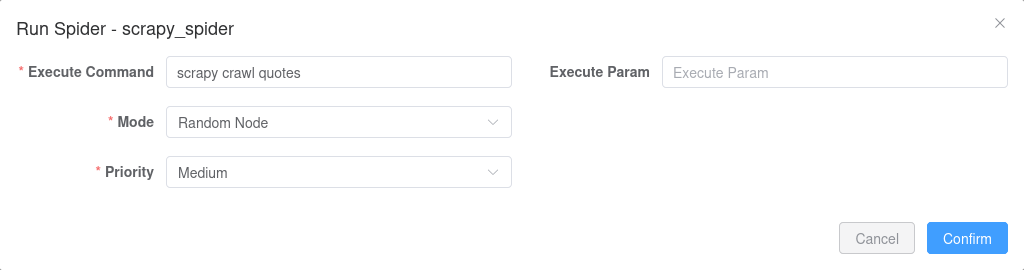
运行爬虫非常简单。
点击播放图标按钮运行,使用默认设置点击确认即可。
查看任务
太好了!我们刚刚触发了一个爬虫任务,可以在任务标签页中查看。点击任务标签页查看。
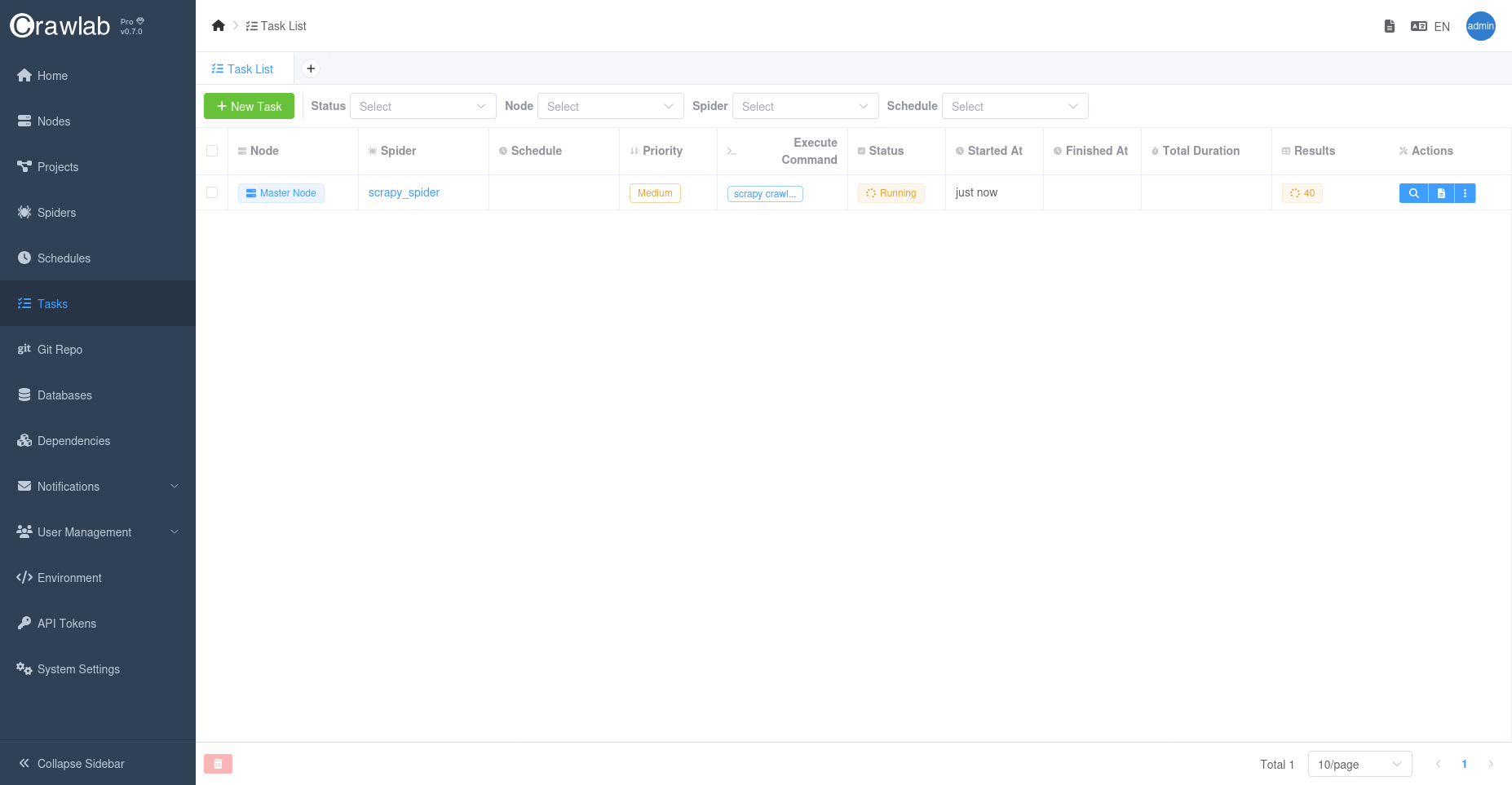
任务正在运行中,点击右侧的查看按钮可以查看任务详情。
点击日志标签页可以查看实时日志。
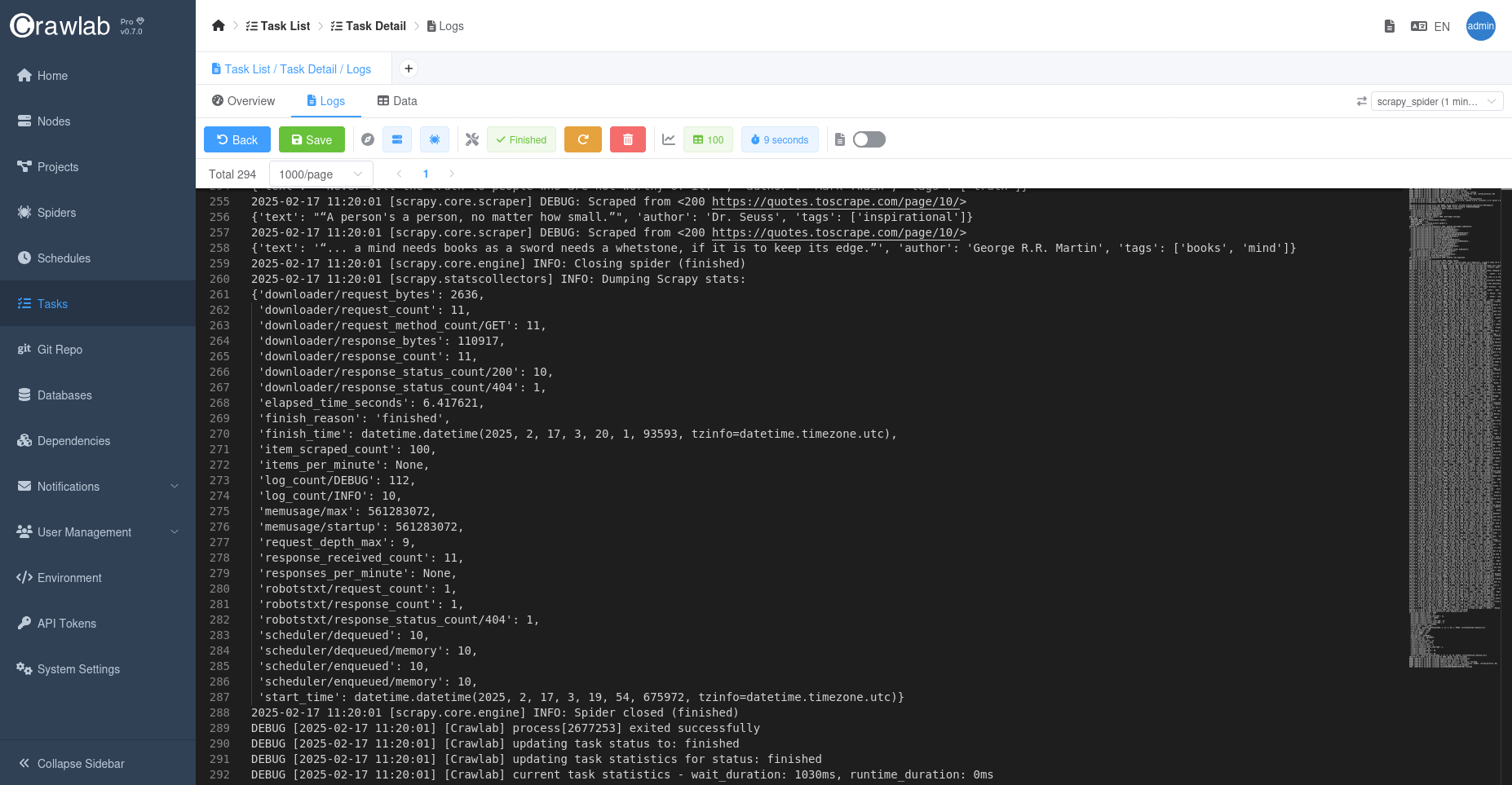
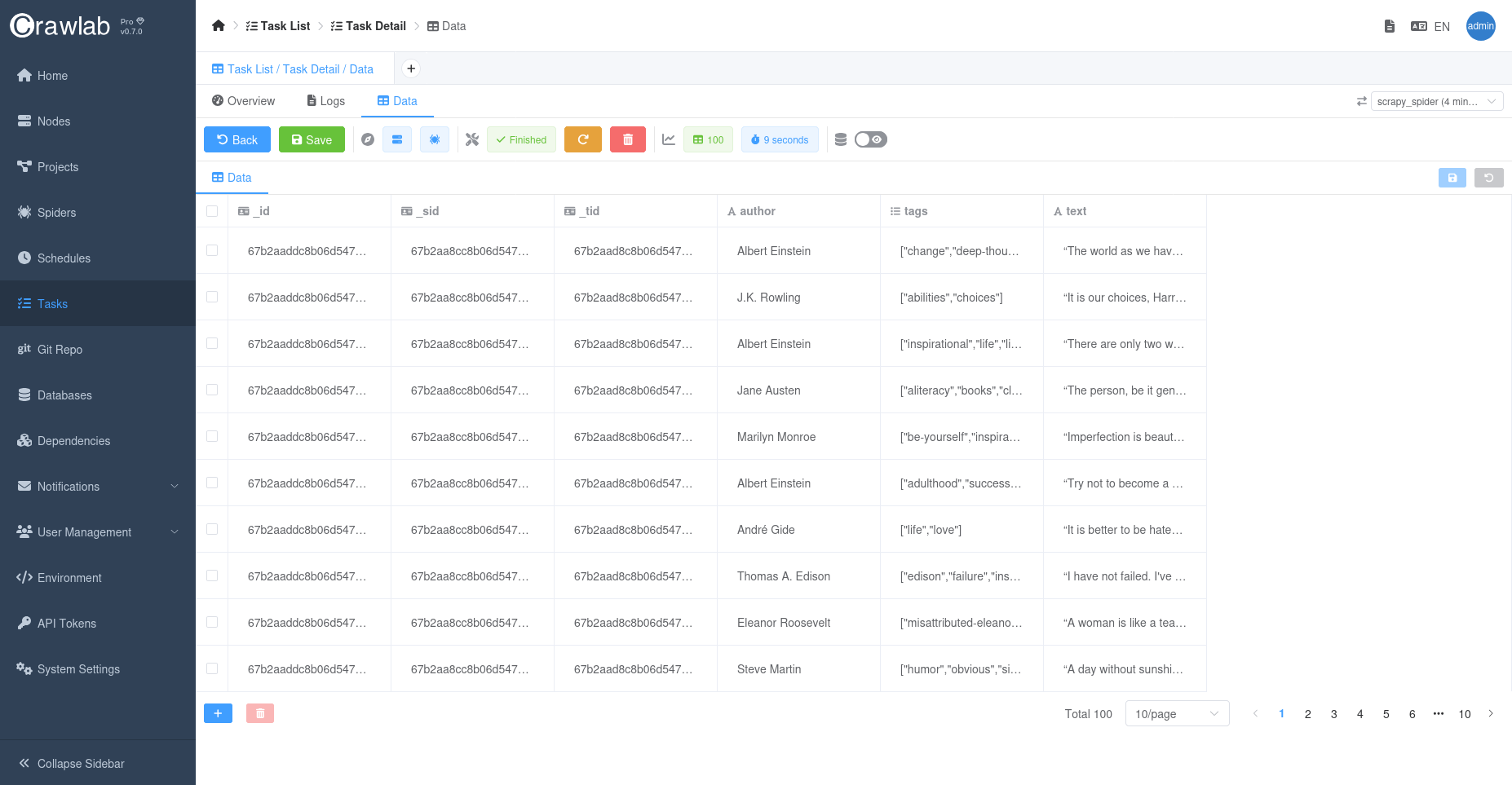
爬虫运行过程中,点击数据标签页可以查看抓取的数据:
总结
让我们回顾一下整个过程。我们遵循了一个简单的流程在Crawlab上运行Scrapy爬虫:
- 在Crawlab上创建Scrapy爬虫
- 触发任务
- 查看实时日志
- 查看抓取数据
接下来做什么
这个快速教程让您对Crawlab的基本使用有了初步了解,包括如何运行爬虫、监控任务日志和查看抓取数据等。但Crawlab的功能远不止这些,它还包含许多其他强大功能。您可以查看本指南的其他章节来学习如何使用这些功能。